
はじめに
SQL Serverを触っていて、「テーブル再編成(REORG)」の情報がほとんど出てこないと感じたことはないでしょうか?
Db2やOracleでは、テーブル再編成はパフォーマンス維持のための重要なメンテナンス作業ですが、SQL Serverでは「インデックスの再構成(REORGANIZE)」や「再構築(REBUILD)」の話ばかりが出てきます。
自分も最初は「なぜSQL Serverだけテーブル再編成がないのか?」と疑問に思いましたが、これは内部構造の違いを理解するとスッと腑に落ちます。
結論から言うと、SQL Serverではクラスタ化インデックスがテーブルそのものを表しているため、「テーブル単位で再編成する」という考え方がそもそも存在しません。
SQL Serverだけ考え方が違う理由
Db2やOracleでは、テーブルとインデックスは別の構造として管理されています。
データはテーブル領域に格納され、インデックスはあくまで検索を高速化するための補助的な構造です。そのため、データの並びや格納状態が崩れてくると、テーブル自体を再編成(REORG)する必要があります。
一方でSQL Serverでは、クラスタ化インデックスを作成すると、そのインデックス構造(Bツリー)の中にデータそのものが格納されます。
つまり、
・インデックスのリーフノード = 実データ
・インデックス構造 = テーブル本体
という関係になっています。
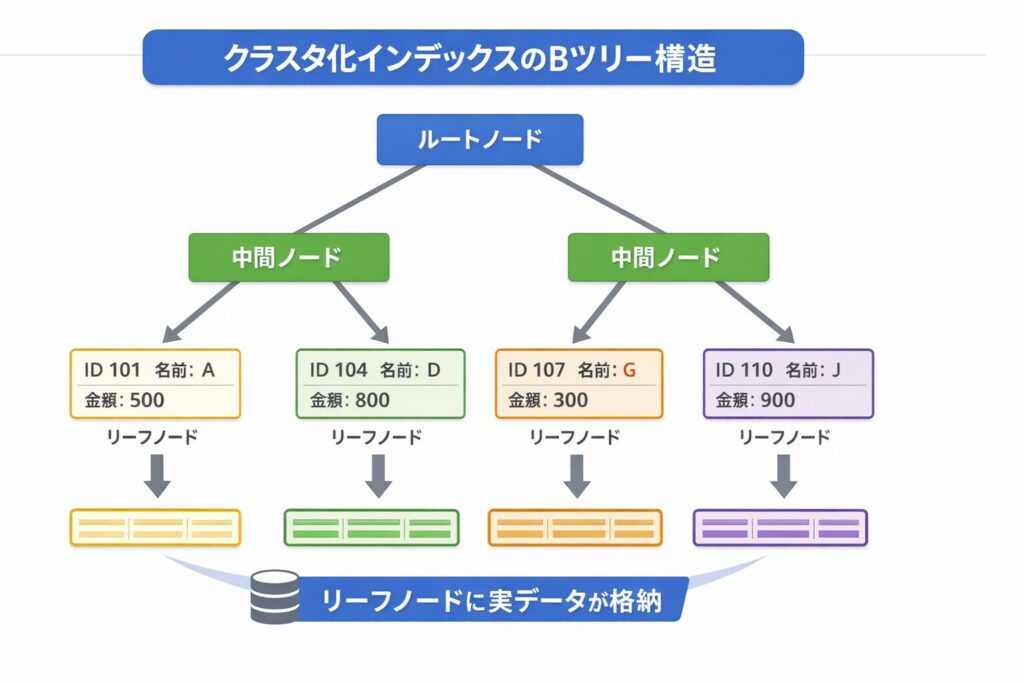
この構造の違いが、「テーブル再編成が存在しない理由」です。
インデックス操作=データの再配置
SQL Serverでは、データは常にインデックス構造の中で管理されています。
そのため、Db2やOracleのように「テーブルを整理する」という発想ではなく、
「インデックスを整理する = データを整理する」
という扱いになります。
これが、SQL Serverでメンテナンスといえばインデックス再構成や再構築の話になる理由です。
例外:ヒープテーブルの場合
ただし、すべてのテーブルがこの構造になるわけではありません。
クラスタ化インデックスが存在しないテーブルは「ヒープテーブル」と呼ばれ、データは順不同で格納されます。
この場合はデータの断片化が発生しやすく、テーブル再編成に近い考え方が必要になります。
ただし、SQL Serverのヒープテーブルは、データ挿入(INSERT)が高速な一方、検索・更新・削除が遅く、大規模データや頻繁な更新には不向きです。
実務ではヒープを避け、クラスタ化インデックスを設計するケースが多いのもこのためです。
ヒープテーブルの詳細については、Microsoftのページが参考になります。

実務ではどうメンテナンスするか
では実際の運用では何をすればよいかというと、テーブルは気にせず、答えはシンプルで「インデックスの断片化を管理すること」です。
SQL Serverでは、断片化の状況に応じて以下を使い分けます。
■ インデックス再構成(REORGANIZE)
・オンラインで実行可能
・軽量な処理
・断片化が軽度の場合に使用
■ インデックス再構築(REBUILD)
・インデックスを作り直す
・負荷が高い
・断片化が大きい場合に使用
一般的な目安としては、
・断片化 5〜30% → REORGANIZE
・断片化 30%以上 → REBUILD
といった使い分けになります。
まとめ
SQL Serverにテーブル再編成がない理由は、クラスタ化インデックスの構造にあります。
・データはインデックスのリーフに格納される
・テーブルとインデックスが一体化している
・そのためインデックス操作=データ整理になる
この構造を理解しておくと、「なぜインデックスだけのメンテナンスなのか」が腑に落ちます。
最初は違和感がありますが、SQL Serverでは「テーブルを見る」のではなく「インデックスを見る」という意識に切り替えることがポイントです。
SQL Serverのメンテナンスについては、以下の記事でも詳しく解説しています。

コメント